1. Introduction
[1.1] Digital fan fiction challenges the sovereignty of the literary object and necessitates a reevaluation of textuality. This process of reevaluation is evident in fan studies with critics such as Abigail De Kosnik writing that "a fan fiction story cannot be viewed as a wholly self-contained object, a text delimited by the first and last words that appear on the screen, the way that readers of novels and other genres of print culture conventionally read books as bounded by their covers" (2016, 254). De Kosnik's distinction between a text on a screen and a novel evokes Gérard Genette's description of a literary work as comprising both a text and supplementary elements, collectively known as the paratext (1997, 1). Digital humanities scholarship has similarly grappled with the distinction between texts and works with Katherine Bode (2018) and Martin Paul Eve (2019) criticizing the discipline for focusing on literary texts and ignoring the ways in which literary works record the activities of transmission that are required to fully understand and contextualize the text.
[1.2] I take fan fiction as a form of networked digital narrative that both exists electronically and shares features with the printed book. Focusing on the paratext as a site of transaction between fan fiction writers and readers, I draw upon Bode's (2018) and Eve's (2019) suggested methods for attending to the negotiation between work and text. Using computational methods—word frequency analysis, topic modeling, and decision trees—to analyze fan fiction paratexts as they are used on the online fan fiction repository Archive of Our Own (hereafter AO3), I reevaluate the fan fiction paratext and the notion of the fan fiction text.
2. Digital methods and the fan fiction text
[2.1] Fan fiction, defined as amateur works of fiction created in response to and depicting the same characters and/or setting of a published media work or works, is predominantly located in massive digital archives, each hosting millions of works. Fan fiction and fan fiction communities are enmeshed in many different conversations—about literariness, digital media, popular media, psychology, politics, and sociocultural activities—and scholars working within these fields and more all bring their disciplinary expertise to bear on fan fiction from many different angles. Arising from these many disciplines, there are two identifiable approaches to fan fiction: the ethnographic and the literary critical, as identified by Kristina Busse and Karen Hellekson, who write that "media fandom studies has historically been the realm of ethnographic research on the one hand and literary textual analysis on the other" (2012, 49). Ethnographic and literary critical approaches can emphasize either the fan or the fan fiction at the expense of the other so that, in the estimation of Adrienne Evans and Mafalda Stasi, "where ethnography risks 'othering' the fan, textual analysis risks making them merely a subject created through textual functions" with the result that "textual analysis risks losing the fan altogether" (2014, 12). Without sacrificing their literary status, it is important to understand fan fiction works within the context of their production and reception.
[2.2] Digital methods, which are "defined as techniques for the ongoing research on the affordances of online media" (Venturini et al. 2018, 4200), have incurred similar criticism to literary critical fan studies methods, namely, that they decontextualize and reify the text, removing it from its social and textual context as a work. One particular method is distant reading, which, in the words of Eve (2019), "is concerned with reductive but nonetheless labor-saving methods that use the untiring repeatability of computational tasks to garner statistically informed deductions about novels or other works that one has not read" (2019, 3). As well as allowing the scholar of literature to transcend the limits of their own reading, distant reading has been championed as enabling detailed and panoramic insights while resisting reliance upon a small canon of works. Franco Moretti, who coined the term distant reading, defines it as a method "where distance…is a condition of knowledge: it allows you to focus on units that are much smaller or much larger than the text: devices, themes, tropes—or genres and systems" (2013, 48–49, original emphasis). These abilities seem well-suited to the study of fan fiction, a form of literature so prolific that reading the more than six million texts on AO3 is impossible for even a large group of researchers. Additionally, fan fiction exists in an electronic format that, as Maria Lindgren Leavenworth notes, is amenable to data collection and analysis (2016, 51).
[2.3] Distant reading has been criticized for misrepresenting the text and removing it from its context. Bode accuses distant reading methods of treating literary texts as stable and discrete objects, as "single entities in time and space" (2018, 26) when, in actuality, "literary works do not exist in a single time and place but accrue meaning in the multiple contexts in which they are produced and received" (40). She seeks to redress this by attending to the constructed, contingent, and transactional nature of works and datasets (42). For Bode, digital methods that treat texts as stable objects ignore their contexts, much as literary critical approaches in fan studies treat fan fiction works as isolated objects and ignore the communities that create, share, and interpret them. Eve (2019), in his work applying distant reading methods to a single literary text, locates editorial differences between the US and UK editions of the novel Cloud Atlas. Extrapolating this potential for difference to e-books, which can be altered even after a copy has been purchased and downloaded, emphasizes the mutability of digital texts (2019, 29). Eve reconceives the stable and discrete text as a "collection of always-'corrupt' parallel texts that, in aggregate, constitute the social and historical event of a work" (27).
[2.4] Eve's (2019) model has much in common with fan fiction where multiple, divergent works are created in response to one or more popular media work. Fan fiction has been theorized as "transform[ing] a text into a communal property between source creators and fan creators" to create "a shared, meta-textual property that can be a collaborative, mutable thing constantly evolving rather than remaining a static, closed object" (Coker 2012, 86). It has been also described as a metatext, which is "the mental construct shared within the fan community" (Jenkins 2013, xlc), a useful term for referring to fan fiction works in aggregate. Fan fiction, as an aggregation of linked texts, refuses a model of stable and discrete textuality. The model of textuality put forth by Bode (2018) and Eve—as something contingent, mutable, recording a transmission history of production and reception and comprising multiple parallel texts—finds a real-world example in fan fiction.
[2.5] In further defining fan fiction I would like to make a distinction between printed books and digital narratives. Printed books are often read as being "bounded by their covers" (De Kosnik 2016, 254) although, as is shown in the discussion of Bode (2018) and Eve (2019), textuality is not so simple. Digital narratives are "narrative texts that are created in and for digital media that are, presumably, at least one step further removed from concepts of the work, the author, and the text as object" (Birke and Christ 2013, 79). Fan fiction's existence on AO3 as a multiauthored, networked metatext puts it firmly in the category of digital narrative, which means that features of transmission that have been theorized in relation to the printed book and even the e-book must be rethought and, for an example of this, I turn to the paratext.
3. The fan fiction paratext
[3.1] Genette defines the paratext as being accompaniments to a text, such as the title, preface, or illustrations "to make present, to ensure the text's presence in the world, its 'reception' and consumption in the form (nowadays, at least) of a book" (1997, 1, original emphasis). For Genette, the paratext's role cannot be overstated as "a text without a paratext does not exist and never has existed" (3). Paratextual material allows a text to be located and recognized as a work by designating a space within the work that is understood as the text. The paratext has been understood as framing a central text (Smyth 2014, 330), but more than this, it constructs the text, forming a contact zone between work and world that designates that inside of it as the text and the outside of it as the author and readers.
[3.2] The paratexts of networked digital fan fiction are not identical to the paratexts of printed books, and therefore it is important to describe how the fan fiction paratext functions, specifically on the website AO3. AO3 is a searchable archive of fan fiction texts. The user interface is minimal, and the search functionality is powerful. The landing page offers orienting information and several ways to access the fan fiction works (figure 1). The works can be accessed via a basic search toolbar, a link to advanced search functions, a link to a browse function, and a link to a fandom drop-down menu that taxonomizes works by the media properties to which they relate. The fandom list is also replicated on the landing page.
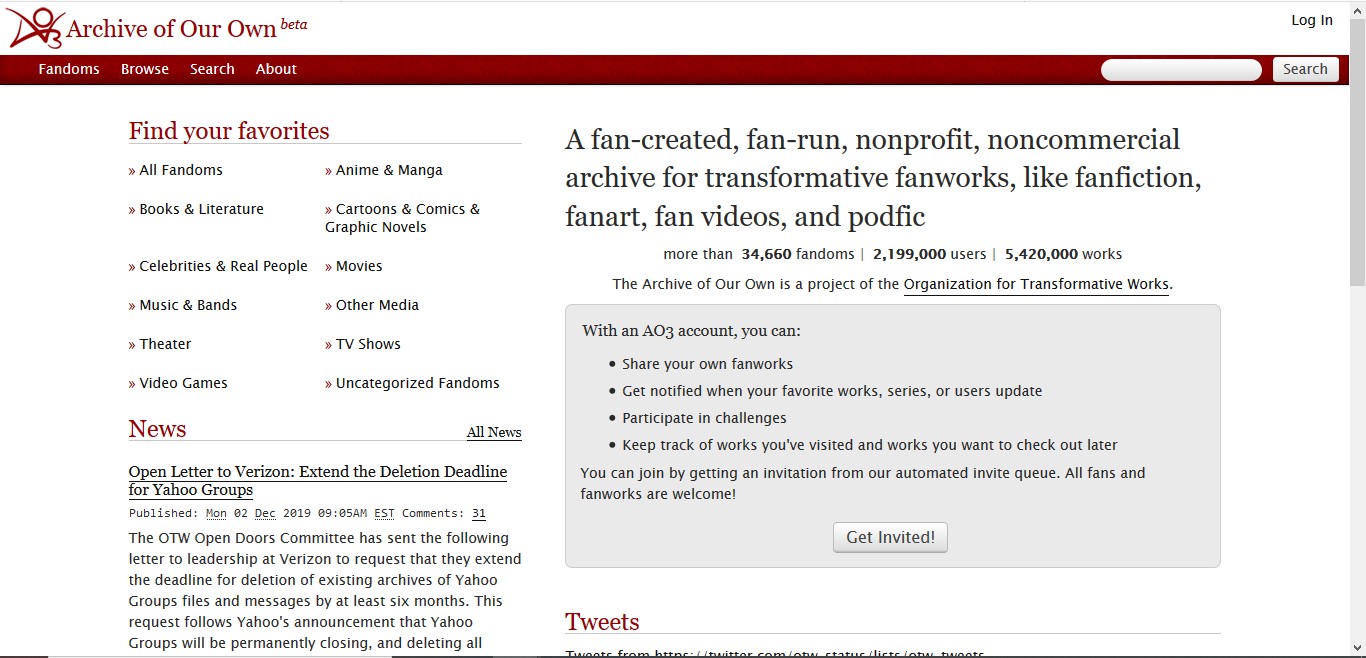
Figure 1. Screenshot of the Archive of Our Own (AO3) landing page, December 2019. https://archiveofourown.org/.
[3.3] Clicking on any of the fandom or browse categories leads to a list of works held on the site, each displayed as a regular set of paratextual material that describes the work and its reception (figure 2). For each work, the site lists the work's title, author(s), date of posting or updating, the fandom(s) to which it belongs, any content warnings, characters, romantic and platonic relationships between those characters, summary, language, whether the work is restricted to website members only, and free tags that elaborate on the work's content. There are also icons indicating the work's rating (from General Audiences to Explicit), category (whether it depicts romantic relationships and, if so, whether they are between characters of the same sex, different sex, or a combination), a reiteration of content warnings, and whether the work is complete or in-progress. All of this information is provided by the user who posts the work to the site. In addition, there are metrics revealing the work's word count, number of chapters, number of collections to which it has been added by readers, number of comments, number of kudos (akin to likes), number of bookmarks, and number of hits. This information is generated by AO3; however, authors can opt not to make all of them visible to readers.
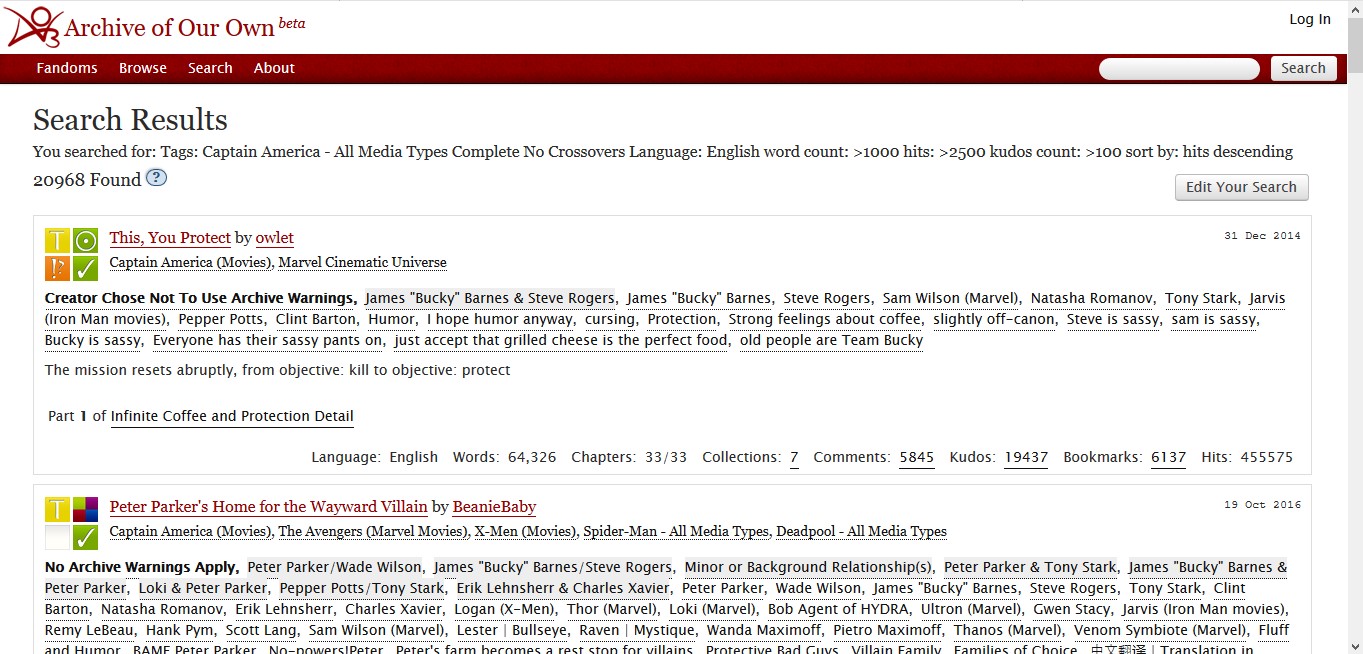
Figure 2. Example of a list of search results on the Archive of Our Own (AO3), December 2019. https://archiveofourown.org/.
[3.4] Once a work has been selected from the list by clicking on its title (figure 3), the reader is taken to a page on the site that replicates the same paratextual material and, in addition, author's notes, the text itself, links to related works and, at the end of the text, a list of readers who gave kudos and finally comments provided by readers.
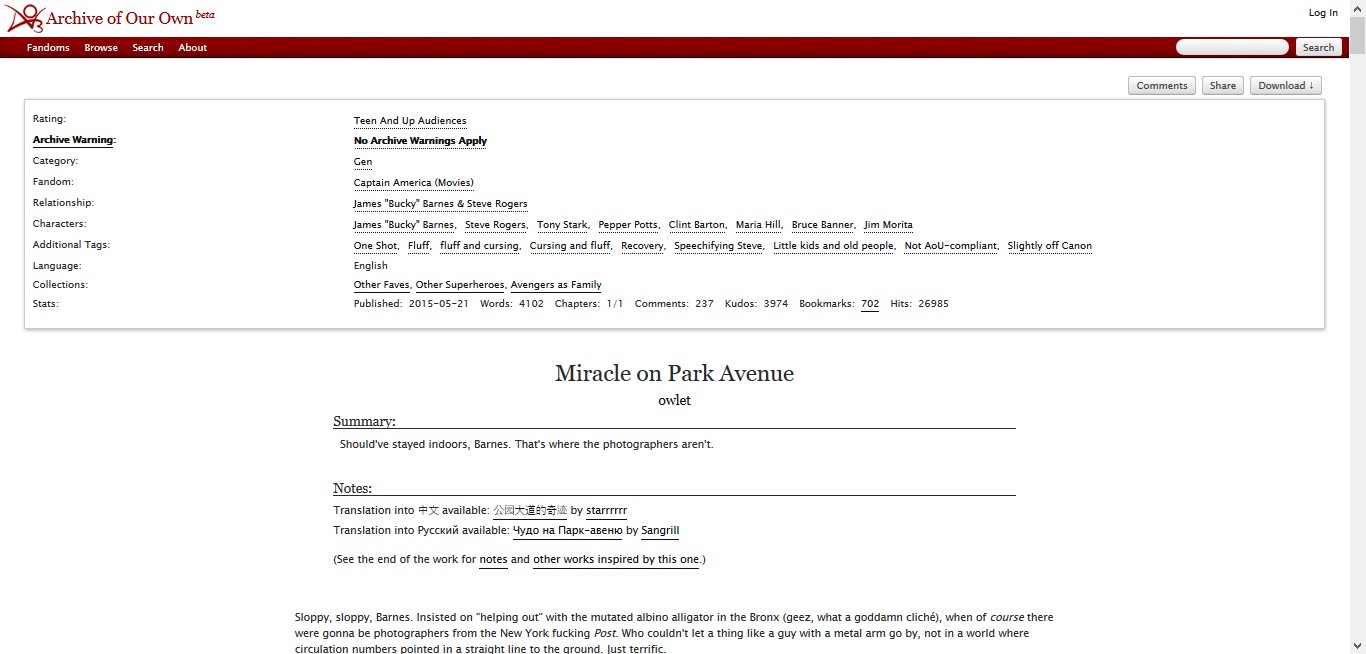
Figure 3. Example of a work on the Archive of Our Own (AO3), December 2019. https://archiveofourown.org/.
[3.5] There are elements of the fan fiction paratext on AO3 that closely resemble the paratextual conventions of the printed book, such as the title and author name(s), and the summary, which is akin to a marketing blurb on a book's back cover. The ability to use hyperlinks in a work's paratext is a major factor in differentiating fan fiction on AO3 from printed books. Not just the author's name, but the fandom, characters, relationships between characters, and free tags each constitute a gateway to a further list of works on AO3 so that "by providing hyperlinks, the e-book [and fan fiction] thus forges connections between texts in ways that are unprecedented in printed books" (Birke and Christ 2013, 77). These hyperlinks not only strengthen associations between the paratexts of different fan fiction texts, creating an intertextual web of connections between individual points in a vast digital narrative, but also help to create a taxonomical organization of the fan fiction works on AO3 that has multiple points of entry. Fan fiction's close connections to other fan fiction texts disincline me from describing each fan fiction text on AO3 as being comparable to a single volume. Rather, selecting and prioritizing various paratextual elements enables the construction of textual objects out of an otherwise undifferentiated networked digital narrative. Constructing a dataset as a contingent but stable textual object for study allows for the application of digital methods.
4. Constructing a dataset
[4.1] In order to interrogate fan fiction paratexts on AO3 in a way that takes into account their multiplicity and connectivity, I constructed the AO3 Dataset from a subset of works on the site. Bode (2018) emphasizes that any conclusions drawn from a dataset will be "shaped profoundly, by the methodological and critical frameworks through which it is approached, and by the selections and amplifications those frameworks produce" (2018, 25). Curating a dataset that enables analysis of the function of paratextual elements in fan fiction requires a series of decisions that I elaborate here. I tried to reduce differences in the content of the texts to amplify the differences between paratextual elements. To construct the AO3 Dataset, I limited the dataset to works with the fandom tag "Captain America (Movies)" due to my familiarity with that fandom. I further limited the dataset to works depicting the relationship pairing "James 'Bucky' Barnes/Steve Rogers" so that a romantic theme and the characters would be constant. I excluded works tagged as crossovers, meaning they belong to more than one fandom, to avoid complicating the dataset. I only included works that can be viewed without a site login, for reasons that I detail in paragraph 4.3. I included only works in English, as this is an English-language study and the computational methods I use require the texts to belong to the same language. I included only works marked as complete as, for a linguistic study of fan fiction texts, the ending of each text may reveal useful data. I included only texts of one thousand words or more as that is the minimum length usually required for the computational method topic modeling. As visitors to AO3 use the paratextual material to choose which fan fiction texts to read, I judged that the more popular fan fiction works would have a better correlation between paratext and textual content. I therefore included works that had been viewed at least five thousand times, meaning that their paratextual material had led to readers frequently selecting that work.
[4.2] These criteria yielded 5,237 works, a number that is large enough to compare different paratextual categories but not so large as to exceed the processing capacity of the digital tools I used. I collected the data from AO3 using a web scraper written in Python initially by Jingyi Li and Sara Sterman (2016) and modified by myself. The AO3 Dataset includes all the paratextual (or metadata) elements of each work as well as the prose narrative that can properly be called the fan fiction text. It does not include reader comments or a list of the readers who left kudos on the work.
[4.3] There is no possibility of constructing a neutral or comprehensive fan fiction dataset even with unlimited time and more processing capacity as every day new works are uploaded to AO3, existing works are updated, and the data regarding hits, kudos, and other categories change. Each of the above choices has an effect on the conclusions I draw but, by detailing the decisions made, I hope to be as transparent as possible in constructing a "stable, historicized, and publicly accessible object for analysis" (Bode 2018, 7). The reproducibility of results is an important and debated issue in the digital humanities; however, using fan fiction data has some specific ethical responsibilities. Due to its nonprofessional and noncommercial status, fan fiction writers are not protected by the same legal strictures as are commercially published authors. With many fan fiction writers using pseudonyms, there is often an attempt to distance fan fiction works from the real-life identities of the authors, and this is not something I wish to undermine. When constructing the AO3 Dataset, I proceeded in line with Amy Bruckman's "Ethical Guidelines for Research Online." She writes that "you may freely quote and analyze online information without consent" providing it has the following criteria: it is officially, publicly archived; no password is required for archive access; no site policy prohibits it; the topic is not highly sensitive (2002, ¶ 1). AO3 is a public archive according to Bruckman's definition as it is accessible without a password. Some works on AO3 are only visible to users of the site who have a username and password, and therefore I excluded such works from my dataset. AO3 does not prohibit the scraping of its contents, stating, "Using bots or scraping is not against our Terms of Service unless it relates to our guidelines against spam or other activities" ("Terms"). The themes depicted in some fan fiction works can be highly sensitive, and so, for this study, I predominantly cite aggregate data (frequently used words and statistically important words) with the addition of some individual titles. Considering the ethical sensitivities of fan fiction data, I am unable to share a full dataset. Instead, I have shared the Python code that I used to collect the data (Appendix A: Code to Scrape Fan Fiction Text and Metadata from AO3) and a list of the URLs of the 5,237 works in the dataset (Appendix B: List of AO3 URLs).
5. Case study: Titles and most frequent words
[5.1] The title has long been a paratextual element. A title points inward to a specific work and, as Eleanor Shevlin notes, it also "participates in the world outside that text" since being "situated on the border of the text, the title commands a far larger audience than the actual work that it labels" (1999, 43). The title synecdochally stands in for a work, distinguishing it from other works and enabling its discussion. Conveying a boundary around and unity upon the work, the title, along with other paratextual elements on the title page, "transform[s] written works into reified products by standardizing the book as a physical product" (46). The title therefore helps to turn a text into a work, which is a discrete physical object that can be differentiated from other works.
[5.2] In addition to these discursive, differentiating, and locational functions, the title has an interpretive function: it gives the reader clues as to the content of the text to which it refers. Moretti describes this function of the title as being like a coded message "where the novel as language meets the novel as commodity" (2009, 134–35). The title, then, operates to distinguish works as physical objects and texts as differentiated content. Fan fiction, as networked digital narrative, challenges the boundaries of both works and texts. Its dissemination via digital archives opposes the idea of works as discrete physical objects and the way that multiple fan fiction texts all participate in the same metatext opposes the idea of texts as separable entities. While the novel title functions to bring stability to individual works—and texts—the fan fiction title likely fulfils another role.
[5.3] In order to compare the functions of the fan fiction title to that of commercially published fiction, I assembled two comparative datasets. The Fan Fiction Titles Dataset (Appendix C) contains the 5,237 titles of the fan fiction works in the AO3 Dataset. The Romance Fiction Titles Dataset (Appendix D) contains 637 titles of romance novel e-books published by Harlequin in their Harlequin Romance category from 2004 to 2013. The Romance Fiction Titles are drawn from a similar genre and a similar timeframe to the Fan Fiction Titles, reducing as many variables as possible. They differ in that the titles in the Fan Fiction Titles Dataset are attached to works of fan fiction disseminated freely on AO3 and those in the Romance Fiction Titles Dataset are attached to novels sold individually on Harlequin.com and other e-book retail sites. Any differences that arise are likely due to both their format—as fan fiction works in a metatext or individual novels—and their commercial status.
[5.4] To gain an overview of the titles, I assembled a list of the most frequent words used in both datasets using the concordancing software AntConc (Anthony 2018) to ascertain differences in their semantic content and paratextual functions. The results are very different (Appendix E: Fan Fiction Titles Word Frequency Results and Appendix F: Romance Fiction Titles Word Frequency Results). The Romance Fiction Titles Word Frequency Results contain 2,743 word tokens and 691 word types, meaning that each word is used 4.43 times. The Fan Fiction Titles Word Frequency Results contain 24,426 word tokens and 4,648 word types, meaning that each word is used 5.25 times, indicating that both datasets are similarly diverse in their word use. However, the Romance Fiction Titles far more frequently use content words than the Fan Fiction Titles, which favor function words.
[5.5] The twenty most frequent words in the Romance Fiction Titles (table 1) feature nine content words and eleven function words. The content words (bride, baby, boss, christmas, marriage, proposal, wife, secret, family) are descriptive of the novels' contents and display a narrow range of themes, with Christmas, marriage, babies, and the male authority figure of the boss recurring. The fifty most frequent words in the Romance Fiction Titles contain thirty-five content words and only fifteen function words that further reinforce these themes. These words give a good indication of the characters, settings, and themes that are depicted in the novels. Harlequin.com labels its novels as belonging to subcategories within the Harlequin Romance category. For the titles in the dataset, these subcategories are Contemporary Romance, Romance, Contemporary Women's Fiction, Family Life Fiction, Holiday Romance, Holiday, Western Romance, Wholesome Romance, Multicultural and Interracial Romance, Contemporary Fantasy, and Regency Romance (Harlequin.com). There is a large crossover between the themes indicated by the Romance Fiction Titles and by these subcategories, indicating that the titles are reflective of the novels' contents. These Romance Fiction Titles enact an interpretive function by relaying clues about the content of the novel to the potential reader.
| Rank | Token |
|---|---|
| 1 | The |
| 2 | S |
| 3 | A |
| 4 | Bride |
| 5 | Her |
| 6 | Baby |
| 7 | To |
| 8 | And |
| 9 | Boss |
| 10 | Christmas |
| 11 | In |
| 12 | His |
| 13 | Marriage |
| 14 | For |
| 15 | Proposal |
| 16 | Of |
| 17 | With |
| 18 | Wife |
| 19 | Secret |
| 20 | Family |
[5.6] The twenty most frequent words in the Fan Fiction Titles (table 2) feature nineteen function words and only one content word. The content word (love) seems redundant as it repeats information already present in the fact that the titles refer to romance narratives only. The fifty most frequent words contain only nine content words and forty-one function words. These content words give character names (bucky, steve, rogers), reinforce a romantic theme, as in love (for example, "This love") and heart ("Wear Your Heart On Your Skin"), or are minimally descriptive, as in home ("Coming Home"), time ("This Time Around"), like ("Just Like Soulmates Should"), and day ("A Day In The Past"). Compared to the Romance Fiction Titles, there is very little cohesion in these content words. The Fan Fiction Titles do not give a summary of the works' themes and therefore do not fulfill an interpretive function.
| Rank | Token |
|---|---|
| 1 | The |
| 2 | A |
| 3 | You |
| 4 | And |
| 5 | I |
| 6 | Of |
| 7 | To |
| 8 | In |
| 9 | Me |
| 10 | It |
| 11 | S |
| 12 | Your |
| 13 | My |
| 14 | For |
| 15 | T |
| 16 | Is |
| 17 | We |
| 18 | Love |
| 19 | On |
| 20 | One |
[5.7] Where the Fan Fiction Titles contain function words relating to characters, this information is already conveyed in the relevant tags of the AO3 paratext: the character and relationship tags. The character and relationship tags can be easily searched and sorted to locate the reader's desired character(s) or relationship(s) while the title can only be organized by means of a less-thorough free text search. If the information about characters in the titles is intended to be used for searching and categorizing, it would be more effective to place that information in the tags. The Fan Fiction Titles, therefore, do not carry the same semantic burden as the Romance Fiction Titles. But do they function to locate, differentiate, and reify fan fiction works as is claimed of novel titles?
[5.8] The Romance Fiction Titles, in their differences, do allow each novel to be differentiated and discussed. However, the similarities between the titles and their repetition of certain words and themes does point toward a similarity in content. Titles like A Bride for the Maverick Millionaire, Millionaire's Baby Bombshell, The Baby Proposal, The Tycoon's Christmas Proposal, Christmas Angel for the Billionaire, and The Bride's Baby cycle around the same narrow range of themes. It is easy to imagine a romance novel reader struggling to remember whether they have already read The Tycoon's Proposal, The Tycoon's Christmas Proposal, or A Surprise Christmas Proposal, or indeed The Sheriff's Doorstep Baby, The Rancher's Doorstep Baby, or Firefighter's Doorstep Baby. The Romance Fiction Titles Dataset, drawn from a specialized and narrow subset of novels, already shows a slippage between discrete works in terms of subject matter that challenges the very idea of works as distinct objects. The Fan Fiction Titles, with their lack of descriptive words, are even less helpful in distinguishing fan fiction texts. The title by itself holds less potential meaning than the other categorizing information: the fandom it relates to, the characters and relationships depicted, the relationship to canon, the genre, the inclusion of explicit sexual content, or the number of words. The titles on AO3 do point toward individual texts by functioning as hyperlinks, but the paratext as a whole, with its abundance of hyperlinks to other works, authors, and fandoms, opens outward to a multitude of linked works.
6. Case study: Texts, author's notes, summaries, and topic modeling
[6.1] My analysis of the most frequent words used in the AO3 Dataset indicates that the title does not act alone to convey information but rather replicates information conveyed in other parts of the paratext, a fact that strengthens the argument that fan fiction is inherently intertextual and also highlights the importance of approaching fan fiction in terms of its organization in online archives. In this section, I use a distant reading technique to gain an overview of the content of the texts, summaries, and author's notes in the AO3 Dataset before conducting a comparison between them. For this I use another computational method in order to offer a different perspective on the data, since one of the benefits of digital methods is the variety of approaches that can be combined and the ability to switch between interpretive lenses and distances, oscillating between close reading and distant reading to traverse "multiple levels of engagement with a corpus of texts" (Templeton 2011, par. 8).
[6.2] Topic modeling is a form of distant reading that provides an overview of a set of texts (or documents) by assuming that the documents have been created using a finite number of themes (or topics) each consisting of semantically related words. For example, a topic containing the words wand, witch, wizard, spell, and potion might be interpreted as constituting the theme of Magic. A children's fantasy story may be comprised of words relating to magic, school, magical creatures, action, and morality. This central assumption of topic modeling—that texts are made up of groups of words that relate to the same theme—is not a huge leap, as Ted Underwood reminds us that "the notion that documents are produced by discourses rather than authors is alien to common sense, but not alien to literary theory" (2012, par. 4). More formally, topic modeling "is an unsupervised statistical classification method for identifying patterns in the use of words within documents and across a corpus" (Bode 2018, 160) and is an effective tool for identifying the "aboutness" of that corpus (Murakami et al. 2017, 244) and hence for identifying the aboutness of fan fiction texts and paratexts.
[6.3] MALLET is a topic modeling tool that uses Latent Dirichlet Allocation (LDA), a probabilistic, machine-learning algorithm created by David Blei that proceeds by splitting a corpus into topics at random, then taking one word at a time from the corpus and, while assuming that the topics it has created are correct, sorting this word into the most likely topic (McCallum 2002; Blei, Ng, and Jordan 2003). It repeats this for every word many, many times over, and as it progresses the topics become stable. The model does not understand the meaning of each word but forms topics from the words that are most frequently associated with each other in the documents and so, after many iterations of the algorithm, remarkably coherent topics emerge. By using topic modeling, one can quickly get a sense of the themes represented in a group of texts and their relative frequencies. LDA "draws structure out of a corpus" with "minimal critical presuppositions" (Templeton 2011, par. 1) and "without reliance on prior hypotheses" (Murakami et al. 2017, 254). The presuppositions it does require relate to practical choices, such as the texts that make up the corpus, the number of topics requested, and the preparation of the texts by removing extraneous words.
[6.4] I extracted from the AO3 Dataset three sets of documents, to form the AO3 Texts Dataset (Appendix G) (5,237 documents), AO3 Summaries Dataset (Appendix H) (5,233 documents), and AO3 Author's Notes Dataset (Appendix I) (4,149 documents). There are fewer documents of summaries and author's notes as not every paratextual element accompanies each work on AO3. As topic modeling identifies semantic similarity based on the cooccurrence of meaning-carrying content words, function words can be removed, so I extracted only the verbs, nouns, adjectives, and adverbs from each document and discarded the rest. I further prepared the documents by removing the character names using a stop-words list I generated from the character field of the paratexts in the AO3 Dataset. As well as transforming the fan fiction works in the AO3 Dataset into these document datasets, there are decisions involved in generating a topic model. I asked the model to find twenty-five topics although "there is no agreed way to automatically decide the number of topics" (Murakami et al. 2017, 250). It should be noted that as LDA is a probabilistic algorithm, the results will vary slightly each time. I generated and used one model for each dataset rather than generating multiple models and cherry picking the one that I preferred. MALLET generates a list of all the topics in a dataset and how prevalent that topic is in the dataset. Words can appear in multiple topics since the words in each topic are not discrete but overlap (Murakami et al., 245) and words can have different connotations (Bode 2018, 160). My discussion below of the three datasets is drawn from these topic lists. MALLET also provides a file with the relative proportion of each topic in each document. These results are important for classifying documents as I do in section 7.
[6.5] Where an analysis of the most frequent words in the Fan Fiction Titles failed to describe the thematic content of the texts in the AO3 Dataset, a topic model succeeds. The twenty-five topics generated from the AO3 Texts Dataset gives an overview of the texts' themes. Of the twenty-five topics identified, some represent setting, plot, and character information sourced from canon, some represent genres and tropes found within fan fiction, and some refer to the texts' style or register, which are more nebulous properties. The model identified canon elements such as the characters of Bucky Barnes (Topic 23: soldier, winter, asset, man, mission) and Steve Rogers (Topic 15: america, shield, avengers, tower, team). There are also topics in common with the Romance Fiction Titles, such as family (Topic 10: baby, kids, dad, mom, boy, love, mother, family, kid, daddy) and weddings (Topic 8: man, husband, room, sir, love, wedding, married, mother, house, family).
[6.6] As well as these easily interpreted topics regarding characters, plot, and settings, there are more ambiguous topics, and these are some of the most prevalent topics in the dataset. Ambiguity is not necessarily a bad thing as Underwood explains: "I want [topic modeling] to point me toward something I don't yet understand, and I almost never find that the results are too ambiguous to be useful. The problematic topics are the intuitive ones—the ones that are clearly about war, or seafaring, or trade. I can't do much with those" (2012, par. 15). The most prevalent topics in the dataset—(Topic 1: time, things, thought, back, good, make, wanted, thing, people, knew), (Topic 11: back, eyes, hand, head, moment, smile, face, lips, door, side), and (Topic 19: time, moment, fact, mind, point, body, words, make, expression, voice)—at first glance appear to be nonspecific though leaning toward descriptions of internal and physical communication. In their analysis of contemporary novels, Jodie Archer and Matthew L. Jockers found that the topics that dominate bestselling novels depicted "people communicating in moments of shared intimacy, shared chemistry, and shared bonds" (2016, 76). These three topics (1, 11, and 19) fit into this category along with topics 24, 6, 13, 14, and 20, which contain similar words and make up 44.97 percent of the dataset. The topics in the AO3 Texts Dataset establish an overview of the texts and so, when looking at the topics in the AO3 Summaries and AO3 Author's Notes Datasets, we can assume that any topics that overlap with the topics in the AO3 Texts Dataset refer to the content of the texts.
[6.7] According to Donata Meneghelli, "in [author's notes] one finds everything, that is, anything: from trivial information about the author's daily life to meta comment on fandom and the functioning of fan fiction; from intertextual hints to references…from disclaimers…to apologies…from autobiographical insights…to pleas for fighting world hunger" (2019, 181, original emphasis). The topic model generated from the author's notes shows that their function is narrower than "everything." The topics generated from the author's notes form several categories relating to the content of the texts, content warnings (Topic 13: warnings, warning, fic, read, violence), apologies for any errors (Topic 19: mistakes, mine, fic, errors, unbeta), and metafictional discussion about the text's creation (Topic 15: end, work, notes, fic, inspired), (Topic 10: story, fic, writing, time, long), (Topic 20: chapter, end, notes, hope, comments), (Topic 6: prompt, written, story, prompts, tumblr), (Topic 7: chapter, end, notes, tumblr, reading), and (Topic 0: title, view, pgwordcount, characters, thirdprompt). Several of the topics are not distinct groups or words, and this arises from the length of the author's notes. LDA usually requires documents of at least one thousand words to produce meaningful results, and the author's notes in the dataset are mostly far shorter than this, some only a few words long. That MALLET has managed to find so many coherent topics from such minimal data is impressive. In these topics, there is information that can be conveyed in other paratextual elements since there are designated fields for content warnings and plot summaries.
[6.8] Three of the topics refer to the communal nature of authorship on AO3 where many authors contribute to the metatext. The author's notes refer to cocreators such as betas (like editors) and artists (Topic 23: beta, art, amazing, story, tumblr), to translations of the text into other languages (Topic 14: russian, translations, https, www.youtube.com/watch, http), or link to social media sites where readers can interact with the author (Topic 16: tumblr, feel, free, follow, find, twitter). For Alexandra Herzog, author's notes "give fan authors the chance to demonstrate their power by publishing stories that are the interpretations of individuals, but which are nevertheless firmly grounded in communally held beliefs about metatext, fan text, and fan fiction in general" (2012, ¶5.3). These topics relating to community challenge the idea of single authorship and therefore have a bearing on an understanding of fan fiction texts as discrete, single-authored objects to "actively undermine the notion of the single author working in solitude and with complete authority over the text" (Leavenworth 2015, 50). Leavenworth is here referring to the active role that readers play in shaping a fan fiction work that is in progress, but this undermining capability can be extended to the role that collaborators such as beta readers, artists, and translators play as well as AO3's interconnected structure itself.
[6.9] The topics present in the summaries are also diverse, relating to elements of canon and generic tropes but also including metafictional reflection. In two topics (Topic 4: prompt, written, fic, tumblr, based) and (Topic: chapter, story, series, fic, read), the summaries reflected writing about the texts. Leavenworth compares the fan fiction summary to the "please-insert" of a printed paratext, which evolved into the "blurb on the back of a book" (2015, 49). From the inclusion of topics similar to those found in the author's notes, it is clear that the fan fiction summary has a less narrow function. While the text remains the location of the story proper, the author's notes convey information about the circumstances of the creation of the text and descriptions of their content in a way that reinforces the intertextuality of the fan metatext. The summary also conveys information about the content of the text and the circumstances of its creation. This repetition and slippage between paratextual elements signal a situation in which paratextual elements do not have individualized roles. As with the titles, no single element can be isolated as carrying the weight of meaning regarding the related text. However, it would be useful to ascertain where the differences lie between summaries and author's notes.
7. Texts, author's notes, summaries, and decision trees
[7.1] Since there is a lot of semantic overlap between the texts, summaries, and author's notes, a method of differentiation is desirable. For this, I use decision trees together with topic modeling. I combined the AO3 Text, AO3 Summary, and AO3 Author's Note Datasets into one larger AO3 Combined Dataset of 14,619 documents and generated a new twenty-five-topic model (see Appendix J for the code and Appendices K and L for the results). Taking the information about the proportion of each topic present in each document, I used a decision tree, which is a supervised learning method, to classify the documents. Starting with a dataset in which each document is labelled as belonging to the text, summary, or author's note class, the decision tree algorithm splits the dataset into a training set and a test set, using the training set to learn which topics are most significant in determining which document belongs to which dataset and then using the test set to verify the accuracy of that hypothesis (Galarnyk 2019). While topic modeling generates a useful overview of documents, decision trees can pinpoint the differences between datasets so that "decision trees provide a means of tying the results of topic modeling to literary works and, more particularly, of associating word patterns with historical categories of documents" (Bode 2018, 159).
[7.2] I generated a decision tree that determines with 92.28 percent accuracy whether a document in the Combined Dataset belongs to the Summaries, Text, or Author's Notes Datasets (figure 4). The differentiating topic (Topic 9: chapter, end, notes, story, work, fic, hope, tumblr, love, comments, writing, reading, write, guys, read, chapters, enjoy, kudos, post, written) reflects metafictional description of the text and paratextual elements. If a document in the Combined Dataset contains less than 0.004 percent of Topic 9, it is most likely to be a text. If it contains more than 0.004 percent but less than 0.254 percent of Topic 9, it is most likely to be a summary. Finally, if it contains more than 0.254 percent of Topic 9 it is most likely to be an author's note. This tells us that texts in the dataset usually do not contain metafictional description of the text and paratextual elements. Author's notes contain a comparatively large amount of metafictional description of the text and paratextual elements and summaries sit somewhere in the middle.
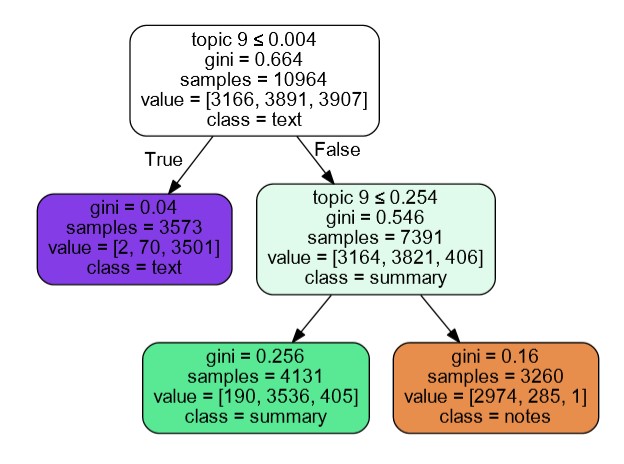
Figure 4. Decision tree classifying summaries, text, and author's notes in AO3 combined dataset.
[7.3] Although there is semantic crossover between the elements of the fan fiction paratext in the AO3 Dataset, the text, summaries, and author's notes still somewhat reflect their traditional roles as, respectively, story, description of story, and metafictional reflection. However, the way that information is shared across the different paratextual elements demonstrates a renegotiation of their role within a digital title page.
8. Conclusion
[8.1] For Nadine Desrochers and Daniel Apollon, the "'digital 'object' requires a rethinking of the concept of 'text'" (2014, xxxii). As Genette (1997) writes, there is no text without a paratext, and this is most visible in online digital narrative. On AO3 the reader must engage with paratextual material in order to get to the text. As I have shown through various computational methods, the elements of the fan fiction paratext on AO3 function differently to those of printed novels and even e-books. The titles of fan fiction on AO3 do not work to unify individual texts or provide information about the text's content and only minimally work to differentiate texts and allow access to them by virtue of being a hyperlink. The author's notes and summaries have multiple overlapping functions, conveying information about the content of the related text and metafictional discussion. Moreover, the information conveyed in the titles, author's notes, and summaries can be and often is duplicated in the various tag fields that AO3 employs. This sharing of functions and repetition between paratextual elements in combination with the extensive use of hyperlinks horizontally connecting the paratexts of multiple works leads to a reevaluation of the paratext as it manifests on AO3. Similarly to the interconnectedness of the texts on AO3 as part of a massively networked metatext, the paratextual material on AO3 is interconnected and forms a paratextual zone of transition between the outside of the website and the texts within it. This paratextual zone is not just a barrier but is actively involved in the construction of texts, which are aggregate objects—akin to datasets—constructed using AO3's search capabilities. With this understanding of textuality, a search query on AO3—for example, works that use the character tag "Harry Potter" and the additional tag "Alternate Universe: Vampires"—constructs a work that contains sixty-four texts (as of December 20, 2019). Approaching fan fiction texts as both literary and digital objects constructed by paratexts and metadata prompts a reconsideration of fan fiction as "bits of code, formulae, rhythmic models, fragments of social languages" that cannot be "reduced to a problem of sources or influences" (Barthes 1981, 39).
9. Acknowledgements
[9.1] A heartfelt thank you to Dr. Anouk Lang, who provided support, academic and otherwise, in the gestation of this article. My thanks also to the reviewers for their extensive feedback and to the entire editorial team.